CLDR 43 Release Note
| No. | Date | Rel. Note | Data | Charts | Spec | Delta Tickets | GitHub Tag | Delta DTD | CLDR JSON |
|---|---|---|---|---|---|---|---|---|---|
| 43 | 2023-04-12 | v43 | CLDR43 | Charts43 | LDML43 | ΔV43 | release-43 | ΔDtd43 | 43.0.0 |
| 43.1 | 2023-06-15 | v43.1 | n/a | n/a | LDML43.1 | ΔV43.1 | release-43-1 | See note in 43.1 Changes | 43.1.0 |
Overview
Unicode CLDR provides key building blocks for software supporting the world’s languages. CLDR data is used by all major software systems (including all mobile phones) for their software internationalization and localization, adapting software to the conventions of different languages. It is important to review the Migration section for changes that might require action by implementations using CLDR directly or indirectly (eg, via ICU).
CLDR 43.1 is a dot release focused on fixing specific issues. For more details for see Version 43.1 Changes.
CLDR 43 is a limited-submission release, focusing on just a few areas:
- Formatting Person Names
- Completing the data for formatting people‘s names, bringing it out of “tech preview”. For more information on the benefits of this feature, see Background.
- Locales
- Adding substantially to the LikelySubtags data
- This is used to find the likely writing system and country for a given language, used in normalizing locale identifiers and inheritance.
- The data has been contributed by SIL.
- Inheritance
- Adding components to parentLocales.
- Documenting the different inheritance for rgScope data, which inherits primarily by region.
- Adding substantially to the LikelySubtags data
- Other data updates
- In English, Türkiye is now the primary country name for the country code TR, and Turkey is available as an alternate. Other locales have been reviewed to see whether similar changes would be appropriate.
- Name for the new timezone Ciudad Juárez
- Structure
- Adding some structure and data needed for ICU4X and JavaScript, for calendar eras and parentLocales.
- All files have been moved from ‘seed’ to ‘common’.
- Collation \& Searching
- Treating various quote marks as equivalent at a Primary strength, also including Geresh and Gershayim.
For details, see below.
Locale Status
The bar for each coverage level increases each release. Faroese (fo) increased from Basic to Moderate, while Cherokee (chr), Lower Sorbian (dsb), and Upper Sorbian (hsb) dropped from Modern to Moderate.
Version 43.1 Changes
Version 43.1 currently in Beta. It is planned to be a dot release that addresses the following issues. The main changes are for compatibility (including parser compatibility and GB 18030-2022 Level 2 support). To access the release data, use the release tag or the json link. The following tickets are included:
GB18030-2022 Compliance
Compatibility
The following changes are included to allow for better compatibility with certain parsers.
- CLDR-16606 Support ASCII space in English time formats between time and AM/PM, using alt=“ascii”
- CLDR-16634 Revert treatment of ‘@’ as ALetter for word break
Other
- CLDR-16247 Decimal and grouping separator for en_ZA does not align with in-country usage
- CLDR-16623 Fix the LDML specification for the locale to use for name formatting
- CLDR-16643 Cyrl ↔︎ Latn should use Kh instead of Ḫ
The only DTD change is the additional of alt=“ascii” for time formats:
<!ATTLIST pattern alt NMTOKENS #IMPLIED > <!--@MATCH:literal/alphaNextToNumber, ascii, noCurrency, variant--> <!ATTLIST dateFormatItem alt NMTOKENS #IMPLIED > <!--@MATCH:literal/ascii, variant-->
Data Changes
DTD Changes
- Person Names (formerly in tech preview in CLDR 42)
- Changed the order, length, usage, formality attribute values to be single elements, not sets.
- Expanded the sample names, and changed two field values (prefix, suffix) to be more descriptive (title, generation, credentials), splitting the suffix because the placement may vary.
- Date Eras
- Eras were accessed only by number. There are now alphanumeric identifiers added with new attributes: an identifying code plus aliases.
- Calendars may inherit eras with the inheritEras element. For example, the Japanese calendar inherits from Gregorian previous to a certain point in history.
- Locales
- The parentLocale elements now have an optional component attribute, with a value of segmentations or collations. These should be used for inheritance for those respective elements. For example, zh_Hant does not normally inherit from zh (since people would get a ransom-note effect with mixed scripts). However, collations can be designed to handle sets of characters for multiple writing systems.
- Likely Subtags now have an attribute to indicate the origin, currently: sil1, wikidata, special.
- Cleanup
- The @MATCH values were not being tested for some entries, so the valid entries were extended for the elements: cr, rbnfrule.
BCP47 Data Changes
- A new timezone short id was added (tz-mxcjs, for Ciudad Juárez), and the description for Istanbul updated the country spelling to Türkiye.
Supplemental Data Changes
- Units
- A new unit was added for the Beaufort scale. Translations are only provided for a few locales that are known to use it.
- Unit preferences were added for floor area, rainfall speed, and snowfall speed. See Units for differences.
- Locales
- Special parentLocales are added for collations and segmentations. See Locale > Parent… for the differences.
- Many new likely subtag mappings were added, thanks to contributions from SIL. See Likely > Subtag for differences.
- Transforms
- Aliases for certain Ethiopic transliterators were added.
- New test transliterators for Jpan, Khmr, Laoo, and Sinh scripts were added. These are intended for testing, not for production (especially for Jpan scripts, which requires NLP for acceptable results).
- See Transforms for the differences.
- Language Info
- Preferred hours were changed for CW (Curaçao).
- Metazones
- Data was changed for 3 zones, and added new metazone for Ciudad Juárez. See Metazone.
Locale Changes
- Person Name Data
- Expanded data was collected for sample names. These are not meant for use in production, but rather to give translators a feeling for how these names would appear with the different the name formatting patterns.
- Data was also collected for more locales, and additional warning messages were added to alert translators about possible problems.
- Inheritance Changes: Data was added due to inheritance changes in order to maintain correctness of the data. Clients shouldn’t need to take any action, but may notice a larger size. However, clients that use mechanisms such as string pools may see no growth at all.
- CLDR data uses two kinds of inheritance:
- vertical — items inherited from parent languages (eg, fr_CA inherits from fr)
- horizontal — items inherited within the same language (narrow Month translations inherit from short ones when the same value is expected for both)
- These can affect two kinds of data:
- missing values — where the locale has no data (eg, no narrow Month translations)
- marked values — where CLDR has a special internal marker, which doesn’t appear in the production data for a release. These specially marked values have always been removed from production data.
- There are a few cases where these modes of inheritance can conflict. To prevent that from happening (both in processing CLDR files and in clients), the internal data has been “hardened” — marked values have been replaced by explicit data values. This makes it more likely that clients that don’t handle horizontal inheritance correctly will end up with the right answer.
- CLDR data uses two kinds of inheritance:
- Updates:
- The term Türkiye is now used for the country instead of Turkey for English (the alternate spelling is also available). Where appropriate, a corresponding term is used in other languages.
- Name for the new timezone Ciudad Juárez
- Locales —The following locales were added, but only have Core level for this release.
- North Levantine Arabic (apc), Choctaw (cho), Lombard (lmo), Papiamento (pap), Riffian (rif)
- Collation \& Searching
- The default collation and searching now treats various quote marks as equivalent at a Primary strength, also including Geresh and Gershayim. In searching they are treated as identical when ignoring case and accents; in collation they are ignored unless there are no primary differences (such as a vs b) and no preceding secondary differences (like a vs â).
- Exemplars
- The exemplar characters for Chinese (zh) now include all TGH 2013 Level 1 characters
- Rule-Based Number Format
- There were various fixes to some locales: see the tickets for more information.
File Changes
New files:
- /common/annotationsDerived/
- bgn.xml, lij.xml, nso.xml, quc.xml, tn.xml
- /common/main/
- apc.xm, apc_SY.xml, cho.xml, cho_US.xml, lmo.xml, lmo_IT.xml, pap.xml, pap_AW.xml, pap_CW.xml, rif.xml, rif_MA.xml
- /common/testData/personNameTest/
- 122 files
- /common/testData/transforms/
- am-Ethi-t-am-ethi-m0-geminate.txt, und-Latn-t-und-ethi-m0-aethiopi-geminate.txt, und-Latn-t-und-ethi-m0-alaloc-geminate.txt, und-Latn-t-und-ethi-m0-beta-metsehaf-geminate.txt, und-Latn-t-und-ethi-m0-ies-jes-1964-geminate.txt
- /common/transforms/
- Japn-Latn.xml, Khmer-Latin.xml, Lao-Latin.xml, Sinhala-Latin.xml, am-Ethi-t-am-ethi-m0-geminate.xml, und-Ethi-t-und-latn-m0-aethiopi-geminate.xml, und-Ethi-t-und-latn-m0-alaloc-geminate.xml, und-Ethi-t-und-latn-m0-beta_metsehaf-geminate.xml, und-Ethi-t-und-latn-m0-ies-jes-1964-geminate.xml
Note: All files were moved from seed to common (see the Migration section)
JSON Data Changes
- JSON packaging changes due to the seed/main merge (CLDR-16425)
- The -modern tier now reflects locales which are actually at modern, not those locales which are targeted to modern. (See CLDR-16465 for a proposal to consider dropping the -modern tier.)
- The -full tier now includes all locales, including those formerly in seed. Use the coverageLevels.json file in the cldr-core package to filter out locales. (See the Migration section, below.)
- There is an “effectiveCoverageLevels” key in coverageLevels.json which contains coverage levels for sublocales.
- parentLocales.json now has new keys for collations and segmentations parent information (CLDR-16425)
- coverageLevels.json has a new key, effectiveCoverageLevels, with calculated coverage levels for sublocales (CLDR-16425)
- unitIdComponents.json, now the _values keys are arrays instead of space-separated strings (CLDR-16373 )
- languages.json and other files no longer include some code-fallback data, such as “apc”: “apc” where the translation is the same as the code. (CLDR-16468)
- For time zone names, clients will need to construct the fallback exemplar city per spec. For example, America/Los_Angeles → “Los Angeles” (last field of the TZID, and turn _ into space).
- For language names, see the locale display name algorithm. The “composed” forms are no longer automatically included in the data. For example, purely composed forms such as “en_GB”: “en (GB)” or “en_GB”: “English (United Kingdom)” are no longer present in the JSON data, unless there is an explicit translation such as “en_GB”:”British English”.
- Implementations should be aware that some und.json files may now be completely missing due to this change.
See the Migration section for general data changes.
Specification Changes
Please see Modifications section in the LDML for full list of items:
- Removed numbering from sections, to allow for more flexible reorganization of the specification in the future.
- Person Names
- Brought Person Name Formatting out of tech preview.
- Described the changes from the fields prefix and suffix to the fields title, generation, and credentials. The problem was that ‘prefix’ and ‘suffix’ are positional terms, whereas the contents may need to change position based on the locale.
- Provided much more detailed algorithms for the whole Formatting Process, including additional processing steps such as Handle missing surname.
- Documented changes in the Sample Name structure (whose primary use is internal to CLDR data collection).
- For more background, the Person Names Guide may be helpful, although it is primarily targeted at CLDR data submitters.
- Locales
- Fixed formatting errors in Likely Subtags.
- Improved the specification information about the effect of locale keywords:
- “fw” keyword for first day of the week in Week Data
- “hc” keyword for hour cycle in Time Data
- “dx”, “lb”, “lw”, “ss” keywords related to line wrapping in Segmentations
- “cf” keyword in Currency Formats
- “ca”, “cf”, “dx”, “fw”, “hc”, “lb”, “lw”, “ms”, “mu”, “rg” keywords updates in Key And Type Definitions
- Parent Locales
- Documented the new component attribute, which provides for different inheritance behavior for different components (such as segmentation or collation).
- Region-Priority Inheritance
- Documented the differences in inheritance for rgScope data, which inherits primarily by region rather than primarily by language.
- Includes small changes in <rgScope>: Scope of the “rg” Locale Key, in Lookup, and in Bundle vs Item Lookup.
- Calendar Data
- Documents new optional code and aliases attributes to eras, which allow string IDs for eras instead of just numbers.
- Data Size Reduction
- Added new section with guidance on how to reduce CLDR data size where necessary.
- Telephone Code Data
- Added pointer to the recommended open-source library libphonenumber.
Growth
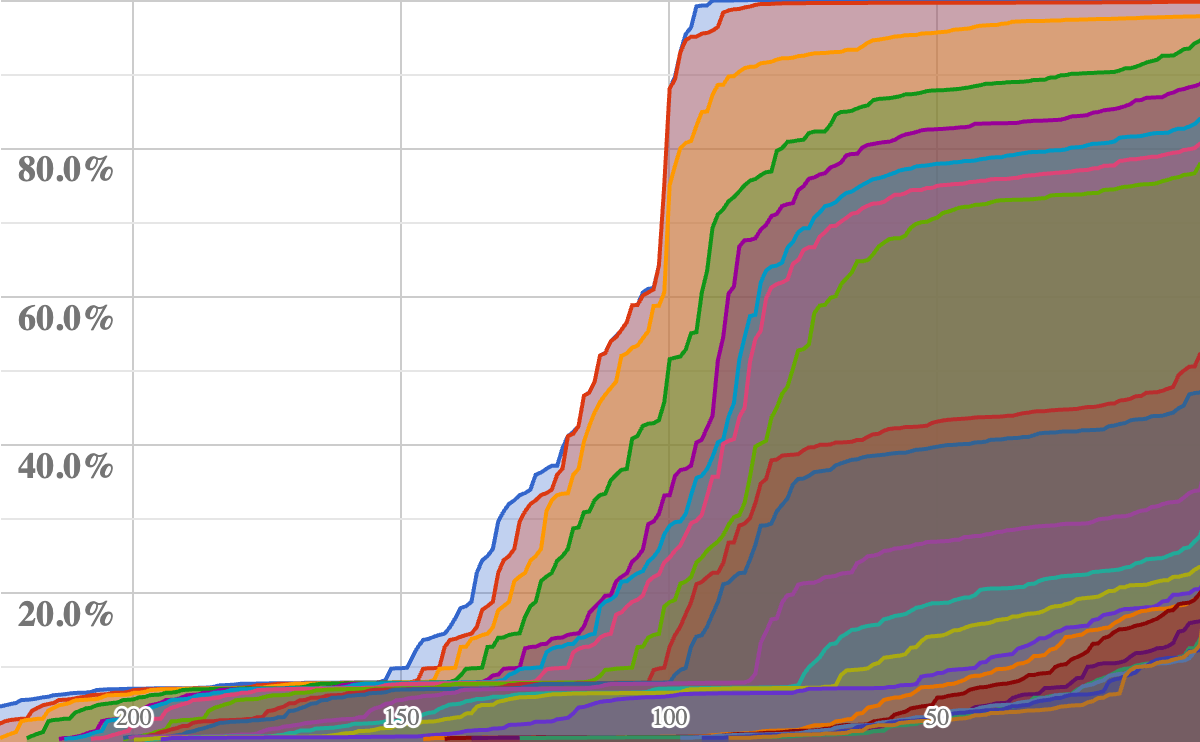
The following chart shows the growth of CLDR locale-specific data over time. It is restricted to data items in /main and /annotations directories, so it does not include the non-locale-specific data. The % values are percent of the current measure of Modern coverage. That level is increases each release, so previous releases had many locales that were at Modern coverage as assessed at the time of their release. There is one line per year, even though there were multiple releases in most years.
The detailed information on changes between v43 release and v42 are at v43 delta_summary.tsv: look at the TOTAL line for the overall counts of Added/Deleted/Changed.
Because this was a limited-submission release, there are a small number of changes visible.
Language Matching
CLDR has data for language matching, as in this chart. The purpose and usage is sometimes misunderstood.
So how is this used? Consider a user whose first language is Breton. If they open an application that only has localizations for English, German, and French, then Breton will not be available. In that case, the data in CLDR can be used to select French as a fallback localization — in the absence of other information.
That last clause is important. The CLDR data is based on the likelihood that a person using language X understands text written in language Y, but large portions of the population for X might prefer other languages.
The CLDR language matching data can and should be overridden whenever there is more information available from a user that allows an implementation to do a better job. It is strongly recommended that systems allow users to not only specify their preferred language, but also any secondary languages in order of priority. Thus a person speaking Kazakh who also knows French could specify French as a secondary language, and get a French localization for an app instead of the CLDR match. This has been done on both Android and iOS, for example.
Important: language matching is different from the CLDR inheritance mechanism: they serve different purposes, and are not aligned. The CLDR inheritance mechanism is how CLDR organizes localized data, and should not be used for language matching. Applications do not need to follow the CLDR inheritance chain.
References: LDML Language Matching, LDML Inheritance vs Related Information, ICU4J Locale Matcher, ICU4C Locale Matcher
Migration
- Seed has been merged into Common (CLDR-6396)
- All files have been moved from the seed/ to the common/ subdirectory.
- Implementations should make use of the common/properties/coverageLevels.txt file (added in CLDR v41) to filter locale files appropriately, in place of depending on incomplete files being in seed. This file and its usage is documented at Coverage Levels. (CLDR-16420).
- Background: Older versions of CLDR separated some locale files into a ‘seed’ directory, which some implementations used for filtering, but the criteria for moving from seed to common were not rigorous. To maintain compatibility with its set of locales used from previous versions, an implementation may use the coverageLevels.txt file filtering for Basic and above, but then also add locales that were previously included.
- Interval Formats
- A small number of interval formats (like “Dec 2 – 3”) have their spacing changed for consistency. This is unlikely to cause problems, as they are similar to a large number of similar changes in v42.
- Person Name Formatting
- Person Name Formatting was in Tech Preview, to allow for feedback. It has now advanced out of Tech Preview and can be used in production. We will continue to enhance the data in subsequent releases, but will now maintain compatibility.
- The field structure for the person name patterns was changed while in Tech Preview. This changed two field values (prefix, suffix) to be more semantically based (title, generation, credentials) instead of positionally based, splitting the suffix because the placement may vary.
- The handling of literals between placeholders in patterns has also changed. For example, when the pattern “{given}•{given2}•{surname}” is used to format a name record [given=Albert, surname=Einstein], the missing field is collapsed and the adjacent literals coalesced, given the equivalent of the pattern “{given}•{surname}”, and thus yielding “Albert•Einstein” rather than “Albert••Einstein”. Beforehand, translators would have to supply an extra pattern to avoid the •• result.
- The handling of spaces in the final formatted string has also changed.
- The specification has been substantially revised to more clearly provide the exact steps to take in formatting a name, so any code formatting person names using the tech preview from v42 must be carefully reviewed and adjusted as necessary.
- Collation
- As usual when there are collation changes, databases may need to re-index sorted fields.
- Locale Inheritance
- The parentLocales now have an optional component attribute. This attribute MUST not simply be ignored; otherwise data from different components could override the main parentLocale data. The attribute specifies inheritance adjustments that should be used for segmentations or collations. For example, zh_Hant does not normally inherit from zh (since people would get mixed scripts). However, collations can be designed to handle sets of characters for multiple writing systems.
- Items marked as rgScope should have different inheritance lookup, which is recommended for the best results. However, implementations that use the general inheritance lookup will see no changes.
- Other New Attributes
- Calendar metadata now has new era attributes (code \& aliases), and element inheritEras, all of which may be ignored if not supported. (CLDR-16469)
- Likely Subtags now have an attribute to indicate the origin of the data. This is informational, and typically be ignored by implementations.
- Turkey / Türkiye
- In v42, the customary English name for the country code TR was “Turkey”, and an alternate name was “Türkiye”. In v43, the customary English name was changed to “Türkiye”, and the alternate name was set to “Turkey”. Translators were advised of the change, and reviewed the names in their locales to see if any needed adjustment. Implementations that wish to retain the English name “Turkey” may choose to use the alternate form.
- Keyboards
- The [CLDR Keyboard Working Group] is working on a major overhaul of the Keyboard specification, released in version 44. “Keyboard 3.0” has a very different goal and therefore existing keyboard files do not interoperate, have not been maintained, and will be removed.
Known Issues
None currently.
Acknowledgments
Many people have made significant contributions to CLDR and LDML; see the Acknowledgments page for a full listing.
The Unicode Terms of Use apply to CLDR data; in particular, see Exhibit 1.
For web pages with different views of CLDR data, see https://cldr.unicode.org/index/charts.