| No. | Date | Rel. Note | Data | Charts | Spec | Delta Tickets | GitHub Tag | JSON Tag | Delta DTD |
|---|---|---|---|---|---|---|---|---|---|
| 44 | 2023‑10‑31 | v44 | CLDR44 | Charts44 | LDML44 | Δ44 | release-44 | 44.0.0* | ΔDtd44 |
| 44.1 | 2023‑12‑13 | v44.1 | n/a | n/a | LDML44.1 | Δ44.1 | release-44-1 | 44.1.0 | See 44.1 Changes |
See Key To Header Links *Note: For NPM, the JSON data uses version 44.0.1
Overview
Unicode CLDR provides key building blocks for software supporting the world’s languages. CLDR data is used by all major software systems (including all mobile phones) for their software internationalization and localization, adapting software to the conventions of different languages.
In CLDR 44, the focus is on:
- Formatting Person Names. Added further enhancements (data and structure) for formatting people’s names. For more information on why this feature is being added and what it does, see Background.
- Emoji 15.1 Support. Added short names, keywords, and sort-order for the new Unicode 15.1 emoji.
- Unicode 15.1 additions. Made the regular additions and changes for a new release of Unicode, including names for new scripts, collation data for Han characters, etc.
- Digitally disadvantaged language coverage. Work began to improve DDL coverage, with the following DDL locales now having higher coverage levels:
- Modern: Cherokee, Lower Sorbian, Upper Sorbian
- Moderate: Anii, Interlingua, Kurdish, Māori, Venetian
- Basic: Esperanto, Interlingue, Kangri, Kuvi, Kuvi (Devanagari), Kuvi (Odia), Kuvi (Telugu), Ligurian, Lombard, Low German, Luxembourgish, Makhuwa, Maltese, N’Ko, Occitan, Prussian, Silesian, Swampy Cree, Syriac, Toki Pona, Uyghur, Western Frisian, Yakut, Zhuang
Locale Coverage Status
The coverage status determines how well languages are supported on laptops, phones, and other computing devices. In particular, qualifying at a Basic level is typically a requirement just for being selectable on phones as a language. Note that for each language there are typically multiple locales, so 90 languages at Modern coverage corresponds to more than 350 locales at that coverage.
Below is the coverage in this release:
Version 44.1 Changes
DTD Changes
- In ldmlSupplemental.dtd, unicodeVersion was corrected to be 15.1.0 (CLDR-17225).
- In ldmlKeyboard3.dtd, the locale element id attribute was incorrectly flagged as @VALUE, fixed (CLDR-17204).
Specification Changes
- The description of the syntax for the -u-dx locale ID key was improved to resolve some ambiguities (CLDR-17194).
- The section on synthesizing emoji sequence names was updated to cover emoji names and keywords for emoji facing-right sequences (CLDR-17230).
Data Changes
- Annotations for emoji facing-right sequences were added (CLDR-17230).
- CLDR tooling was improved to better fix cases when multiple spaces of different types were used instead of single space, and was then used to find and fix cases where a normal space was used in combination with NARROW NO-BREAK SPACE or THIN SPACE (CLDR-17233). This affected 6 locales: fr, hi_Latn, ku, pap, syr, vi.
Data Changes
DTD Changes
The following is a summary of the DTD changes which reflect changes in the structure. The relevant ones are described more fully in the data changes.
LDML
- characterLabels - characterLabelPattern addition of ‘facing-left’ and ‘facing-right’ to support Unicode 15.1 emoji that can face different directions.
- contextTransformUsage - many more values allowed for the type attribute (previously it only supported a subset of the documented values)
- dateFormatItem and intervalFormatItem - many more skeletons allowed for the id attribute, for example EEEEd, GyMEEEEd, GyMMMEEEEd, GyMMMMEd …
- territory - added two alternative names for the territory “IO”: “British Indian Ocean Territory” and “Chagos Archipelago”
- personNames
- Added two new parameter defaults for length and formality. These allow users to set the most customary values used in their language for common usage.
- Added a new field nativeSpaceReplacement. This can be used in languages that don’t normally use spaces between words.
Supplemental Data
- convertUnit/systems - additional unit systems have been added, for finer-grained distinctions.
- unitQuantity/descriptions - descriptions can be added for unit quantities (such as length, area, etc.)
BCP47
- key/types - allow for an IANA parameter for timezones, so that the current ‘canonical’ timezone can be identified and used.
Keyboards
- see “Keyboard Changes”, below.
BCP47 Changes
- The Islamic calendar is now described as Hijri calendar in English, and may have also changed in other locales.
- The new iana attribute provides the time zone ID used in zone.tab file in IANA time zone database if CLDR long canonical ID is different. For example, iana attribute value is “Asia/Kolkata” for CLDR long canonical ID “Asia/Calcutta”.
Supplemental Data Changes
- New locales were added, including en_ID and es_JP, plus many locales at a Basic level.
- Fixes
- There was a fix made for the Zanb script, which was mistakenly categorized as special instead of regular.
- There was a fix made to the BCP47 Latin↔︎ASCII transliterator ID
- Units
- The gasoline-energy-density unit (used in miles per gallon of gasoline equivalent (MPGe) for electric vehicles) and the pint-imperial (used in the UK), plus many Japanese traditional units were added.
- The unit of wind speed, Beaufort, was added for translation in locales where it is used.
- Remaining SI units were added. Because these are primarily of use in scientific fields, they are not translated.
- A few traditional English units were added, such as chain and fortnight. These were not translated.
- Many traditional Japanese units were added. These were not translated, aside from Japanese and English.
- Many units have more refined (and sometimes corrected) unit systems.
- The new SI prefixes for powers of 10 have generally been added: 30, 27, -27, -30. In some non-Latin-script languages there are not yet standard names for these, and in those the prefixes are left with Latin characters.
- Likely Subtags — general cleanup
- Addition of data donated by SIL for determining the most likely script and region for languages.
- Addition of more und_ mappings. These provide for getting a default language if only the script, region, or both are known. These are, however, of limited usage, so implementations may want to filter them out.
- Removal of macroregion codes, such as und_002. These were of very limited utility, and have been removed.
- Language Containment Groups
- Additional mappings have been added.
- Plural rules — have been added for blo.
- Preferred hour formats — have changed substantially for many Latin American locales.
Locale Changes
- There were general changes to fix the lenient parsing set for $. (The previous format for entering Unicode characters led to not escaping $; the new format is more forgiving.)
- Many locales changed the name for the code IO, “British Indian Ocean Territory”, to names similar to “Chagos Archipelago”. Now there are two alternate names, so implementations can use the name that works best for them.
- The name of the Islamic calendar has been changed in English (and many other locales) to use the more descriptive name “Hijri calendar”.
- Some flexible date formats may use different spacing.
- Sierra Leone changed their currency — the new names are available, and the old names have an appended date range.
- The Kyrgyzstan narrow currency symbol “⃀” is now used. (Note: CLDR typically holds off on using new Unicode characters for currencies for a few cycles, to allow system fonts to catch up.)
- There was a concerted effort to fix the Person Name Formatting data for a number of locales.
- There was a concerted effort to fix the names of certain units of measurement for many locales.
- The names and search keywords of new emoji in Unicode 15.1 have been added.
- Many languages added search keywords for symbols like ◉, ⋂, ⊆
- Languages made improvements to other items as needed per language.
File Changes
(Aside from locale files)
Additions:
New XSD files in /common/dtd/.
These correspond to the DTDs, but do not carry the extra validity annotations.
- ldml.xsd, ldmlBCP47.xsd, ldmlSupplemental.xsd, xml.xsd
New Test Data files in /common/testData/
- localeIdentifiers/likelySubtags.txt
- personNameTest/_header.txt, _readme.txt, chr.txt, sw_KE.txt, tg.txt, ti.txt, wo.txt
- transforms/und-t-und-latn-d0-ascii.txt (changed name)
Removals:
Files with insufficient data:
- /common/testData/personNameTest/br.txt, brx.txt, gaa.txt, ks_Deva.txt, lij.txt, pcm.txt, sat.txt, syr.txt, to.txt, tt.txt, xh.txt
Old format keyboards were removed (see Migration):
- /keyboards/
JSON Data Changes
- Available at: https://github.com/unicode-org/cldr-json/releases/tag/44.0.0
- Note that the version number in npm is “44.0.1” instead of “44.0.0”. The version
Keyboard Changes
Keyboard has a new DTD (keyboard3.dtd and the <keyboard3> element). This is a complete rewrite of the specification by the CLDR Keyboard Working Group, and is available as a technical preview in CLDR version 44. See TR35 Part 7: Keyboards. The prior DTDs are included in CLDR but are not used by CLDR data or tooling.
Note that there are additional sample keyboard data files in progress which were not complete for v44, but may be consulted as samples:
Note: Prior keyboard data files are not compatible, have not been maintained and have also been removed in CLDR v44. The prior keyboard files are still available from earlier CLDR downloads, but are not recommended for use as they are known to be incorrect and are not compatible with the current DTD.
See the Known Issues section for additional known issues.
Specification Changes
Please see Modifications section in the draft spec for the list of current changes.
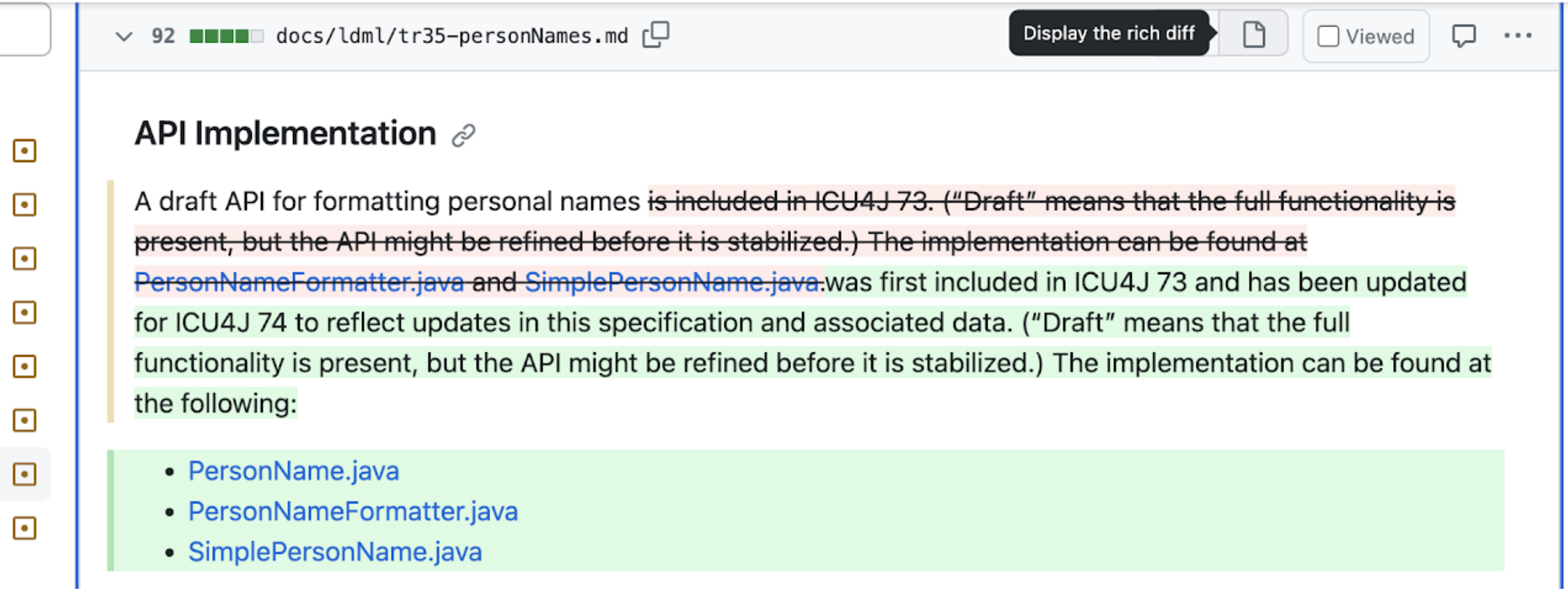
A diff of the changes since CLDR 43 can be viewed here in GitHub, which was last updated on 6 October 2023. Clicking on the rich-diff icon for a page ( 📄 ) will often show the differences with a rich diff, such as the following:
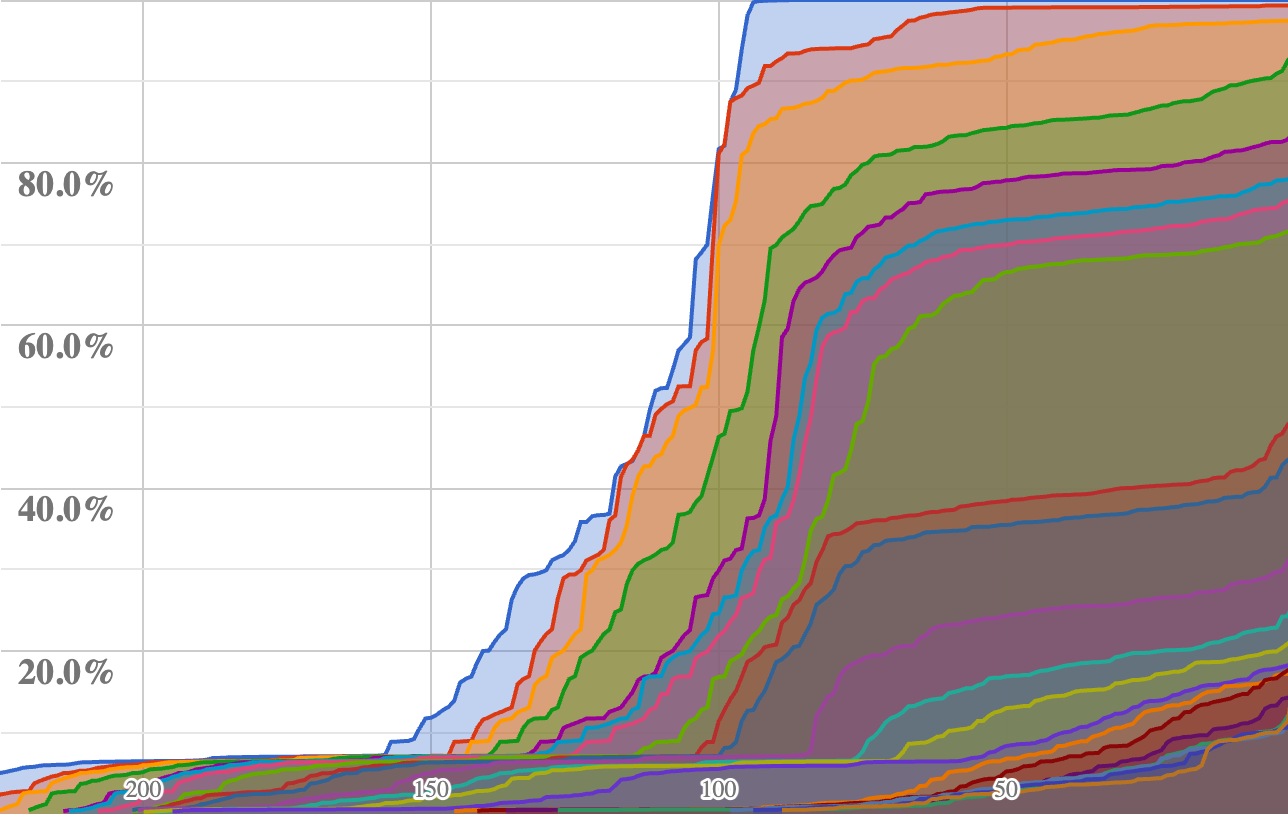
Growth
The following chart shows the growth of CLDR locale-specific data over time. It is restricted to data items in /main and /annotations directories, so it does not include the non-locale-specific data; nor does it include corrections (which typically outnumber new items). The % values are percent of the current measure of Modern coverage. That level is increases each release, so previous releases had many locales that were at Modern coverage as assessed at the time of their release. There is one line per year, even though there were multiple releases in most years.
There were generally a relatively small number of additions this cycle; the focus was improvements in quality, and changes will not show up below.
Migration
- Unit systems provide information about general usage of units of measure. For example, “knot” is in the customary US and UK systems, but is also acceptable for use with SI.
- Implementations using the unit systems will find that some units have changed systems (either to be finer-grained, or to incorporate corrections.
- LikelySubtags are used to find the most likely missing subtags in a locale identifier, and also the minimal form. Thus “de” (German) expands to “de-Latn-DE” (German written in Latin script as used in Germany), and all of (“de-Latn-DE”, “de-DE”, “de-DE”) minimize to “de”.
- The algorithm for lookup has changed slightly (favoring script over region), and there have been data changes: most macroregions are gone (such as mapping from und-003) and some other und mappings. There remain some xx-YYY-001 results for artificial languages.
- Preferred hour formats indicate the preferred form for a locale: 11 PM vs 23:00 vs 11 in the evening.
- Have changed substantially for many Latin American countries
- Keyboard has a new DTD (keyboard3.dtd and the <keyboard3> element). See the “Keyboard Changes” section.
- PersonNames: In the process of moving out of Tech Preview, there were structure additions but also changes:
- The nameField type prefix was replaced with title, and the nameField type suffix was replaced with two new types generation and credentials.
- The sampleName types givenOnly, givenSurnameOnly, given12Surname, full were replaced with new types separating samples for names in the locale from samples for foreign names: nativeG, nativeGS, nativeGGS, nativeFull, foreignG, foreignGS, foreignGGS, foreignFull
- Redundant values that inherit “sideways” may be removed in production data: Some data values inherit “sideways” from another element with the same parent, in the same locale. For example, consider the following items in the en locale, some added in CLDR 44 to provide clients a way to explicitly select a particular variant across locales (instead of using the default):
<territory type=“IO”>British Indian Ocean Territory</territory> <!-- The locale default, matches one of the alt forms -->
<territory type=“IO” alt=“biot”>British Indian Ocean Territory</territory> <!-- explicit “biot” variant” -->
<territory type=“IO” alt=“chagos”>Chagos Archipelago</territory> <!-- explicit “chagos” variant” --> Both alt forms inherit sideways from the non-alt form. Thus in this case, the “biot” variant is redundant and will be removed in production data. Clients that are trying to select the “biot” variant but find it missing should fall back to the non-alt form. Similar behavior occurs with plural forms for units, where some plural forms may match and thus fall back to the “other” form. - Since the last release, Unicode updated its outbound license from the “Unicode, Inc. License - Data Files and Software” to the “Unicode License v3”. All of the substantive terms of the license remain the same. The only changes made were non-substantive technical edits. The new license is OSI-approved and has been assigned the SPDX Identifier Unicode-3.0.
Known Issues
- The region-based firstDay value (see weekData) is currently used for several different purposes:
- The day that should be shown as the first day of the week in a calendar view.
- The first day of the week (day 1) for weekday numbering.
- The first day of the week for week-of-year calendar calculations.
These are not always the same. In the future, some of these functions will be separated out; see CLDR-17095.
- The test data file likelySubtags.txt has an error for input “qaa-Cyrl-CH”; the result should not be empty string as shown, it should either be FAIL or the input string (pending spec clarification). See CLDR-17150.
- The spec for -u-dx bcp47 subtag syntax requires further clarification. See CLDR-17194 . This is fixed in version 44.1.
- Subdivision translations were only updated on a limited basis.
- Use 44.0.1 for CLDR 44 JSON NPM since 44.0.0 was tagged incorrectly.
- unicodeVersion in ldmlSupplemental.dtd was not updated to 15.1 See CLDR-17225. This is fixed in version 44.1.
- Missing derived emoji annotations CLDR-17230. This is fixed in version 44.1.
- There was an error in the Keyboard3 DTD in the <locale> element. It is corrected in version 44.1, see CLDR-17204
- The keyboard charts were not able to generate properly due to DTD changes. It is corrected in version 44.1. (This fixed code was used to generate the charts for version 44.) CLDR-17205
Acknowledgments
Many people have made significant contributions to CLDR and LDML; see the Acknowledgments page for a full listing.
The Unicode Terms of Use apply to CLDR data; in particular, see Exhibit 1.
For web pages with different views of CLDR data, see http://cldr.unicode.org/index/charts.