Unicode Sets
Format
Certain fields have sets of characters (and strings) as values, called Unicode Sets. These have the following format in CLDR 44 or later:
- Each character or string is separated from others by a space. For example, the following are letters used in Croatian. Notice that dž, lj, and nj have no spaces between them: that means that they are strings, not single characters.
- a b c č ć d dž đ e f g h i j k l lj m n nj o p r s š t u v z ž
- Be careful not to omit the spaces: ab c is not the same as a b c!
- A range of characters can be represented with the ➖ character. For example
- A➖E is equivalent to A B C D E
- 가➖힣 is equivalent to typing 11,172 separate characters
- Special characters can be represented by ❰…❱, called an escape.
- For example, ❰NBSP❱ represents a non-breaking space.
- Any character can also be represented by its Hex value. Thus typing either φ or ❰03C6❱ has the same effect.
- See the table on the left; you can copy an escape from the left column to insert into a Unicode Set
- The ➖, ❰, and ❱ characters are chosen to be unusual, so that it is unlikely that they would be normally among the characters you would want to have in a set such as the punctuation characters used in your language
- You can add characters in any order: they’ll be displayed in the default order for your locale. Exceptions are very large character sets like Korean Hangul, which use a code point order so that they can make use of the ➖ character.
In CLDR 43 and previous versions, a different format was used, one that require special “escapes” for certain characters and for strings. This caused problems for many people, and was replaced by the simpler format above.
Key to Escapes
| Abbr. | Code Point | Short Name | Formal Name | Description |
|---|---|---|---|---|
| ❰TSP❱ | U+2009 | Thin space | 🟰 | A space character that is narrower (in most fonts) than the regular one. |
| ❰NBSP❱ | U+00A0 | No-break space | 🟰 | Same as space, but doesn’t line break. |
| ❰NBTSP❱ | U+202F | No-break thin space | NARROW NO-BREAK SPACE | Same as thin space, but doesn’t line break. |
| ❰ALB❱ | U+200B | Allow line break | ZERO WIDTH SPACE | Invisible character allowing a line-break. Aka ZWSP. |
| ❰NB❱ | U+2060 | No-break | WORD JOINER | Invisible character preventing a line break. |
| ❰NBHY❱ | U+2011 | No-break hyphen | NON-BREAKING HYPHEN | Same as a hyphen, but doesn’t line break. |
| ❰SHY❱ | U+00AD | Soft hyphen | 🟰 | Invisible character that appears like a hyphen (in most fonts/languages) if there is a line-break after it. |
| ❰NDASH❱ | U+2013 | En dash | 🟰 | Slightly wider (–) than a hyphen (-), used for ranges of numbers or dates in some languages. |
| ❰ZWNJ❱ | U+200C | Cursive non-joiner | ZERO WIDTH NON-JOINER | Breaks cursive connections, where possible. |
| ❰ZWJ❱ | U+200D | Cursive joiner | ZERO WIDTH JOINER | Forces cursive connections, if possible. |
| ❰LRM❱ | U+200E | Left-right mark | LEFT-TO-RIGHT MARK | For BIDI, invisible character that behaves like Hebrew letter. |
| ❰RLM❱ | U+200F | Right-left mark | RIGHT-TO-LEFT MARK | For BIDI, invisible character that behaves like Latin letter. |
| ❰ALM❱ | U+061C | Arabic letter mark | 🟰 | For BIDI, invisible character that behaves like Arabic letter. |
| ❰ANS❱ | U+0600 | Arabic number sign | 🟰 | For use in Exemplar sets |
| ❰ASNS❱ | U+0601 | Arabic sanah sign | ARABIC SIGN SANAH | For use in Exemplar sets |
| ❰AFM❱ | U+0602 | Arabic footnote marker | 🟰 | For use in Exemplar sets |
| ❰ASFS❱ | U+0603 | Arabic safha sign | ARABIC SIGN SAFHA | For use in Exemplar sets |
| ❰SAM❱ | U+070F | Syriac abbreviation mark | 🟰 | For use in Exemplar sets |
| ❰SP❱ | U+0020 | Space | 🟰 | ASCII space, for use in Exemplar sets |
| ❰RANGE❱ | U+2796 | Range syntax mark | HEAVY MINUS SIGN | heavy minus sign, for use in Exemplar sets |
| ❰ESCS❱ | U+2770 | Escape start | HEAVY LEFT-POINTING ANGLE BRACKET ORNAMENT | heavy open angle bracket, for use in Exemplar sets |
| ❰ESCE❱ | U+2771 | Escape end | HEAVY RIGHT-POINTING ANGLE BRACKET ORNAMENT | heavy close angle bracket, for use in Exemplar sets |
| ❰…❱ | U+… | other | … = hex notation |
The 🟰 indicates that the formal name is the same as the Short name (except for casing).
Input
In Alphabetic Information > Characters in Use and Alphabetic Information > Parse you can just copy in the Symbol listed above. Otherwise, you can use the Formal Name above in your CharacterViewer or CharMap, or use an Option/ALT combination with the Code Point. See also Unicode Characters on Mac and Special Characters in Windows.
On a Mac, be sure to install the Unicode Hex Input keyboard in Settings.
That will enhance your Character viewer, allowing it to recognize each the Formal Name and Code point in the search box.
Note that you won’t be able to see the invisible characters (such as THIN SPACE); but you can select them.
There are also a few direct option sequences, such as Option - for NDASH and Option spacebar for NBSP.
Examples
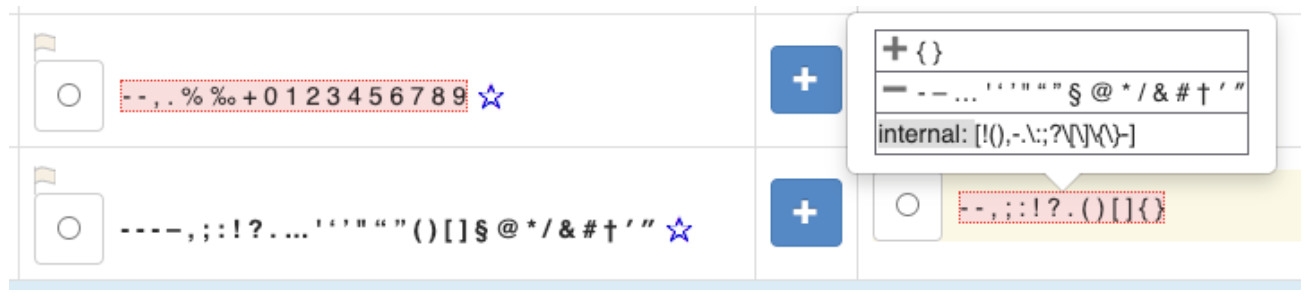
In the info panel, a mouse hover over the non-winning values shows a comparison to the Winning value. The ➕ { } indicates that { and } are additions to the Winning value, and ➖ ‐ – … ‘ ‘ ’ “ “ ” § @ * / & # † ′ ″ indicates that ➖, ‐. –. …. and so on are subtractions from the Winning value. That makes it much easier to see what the difference in the outcome would be.
The very last line shows an internal UnicodeSet format. You can normally ignore this. However, if you want more details about the characters you can copy the […] from that line in the Info Panel and paste that into the Input box on UnicodeSet (and hit Show Set) to see more information about the characters, such as [!(),-.\:;?\[\]\{\}‑].
Exemplar Characters
The exemplar character sets contain the commonly used letters for a given modern form of a language. These are used for testing and for determining the appropriate repertoire of letters for various tasks, like choosing charset converters that can handle a given language. The term “letter” is interpreted broadly, and includes characters used to form words, such as 是 or 가. It should not include presentation forms, like U+FE90 ( ﺐ ) ARABIC LETTER BEH FINAL FORM, or isolated Jamo characters (for Hangul).
- For charts of the standard (non-CJK) exemplar characters, see a chart of the standard exemplar characters.
- For more information, please see Section 5.6 Character Elements in UTS#35: Locale Data Markup Language (LDML).
There are different categories:
| Category | English Example | Meaning |
|---|---|---|
| main letters | a b c d e f g h i j k l m n o p q r s t u v w x y z | The minimal characters required for your language (other than punctuation). The test to see whether or not a letter belongs in the main set is based on whether it is acceptable in your language to always use spellings that avoid that character. For example, English characters do not contain the accented letters that are sometimes seen in words like “résumé” or “naïve”, because it is acceptable in common practice to spell those words without the diacritics. If your language has both upper and lowercase letters, only include the lowercase (and İ for Turkish and similar languages). This list may contain combining marks: if they are only used with a small set of letters, include just those sequences; otherwise you can add them as free-standing characters (between spaces). |
| auxiliary | á à ă â å ä ã ā æ ç é è ĕ ê ë ē í ì ĭ î ï ī ñ ó ò ŏ ô ö ø ō œ ú ù ŭ û ü ū ÿ | Additional letters and punctuation (beyond the minimal set) used in foreign, old-fashioned, or technical words found in typical magazines, newspapers, etc. For example, you could see the name Schröder in English in a magazine, so ö is in the set. However, it is very uncommon to see ł, so that is not in the auxiliary set for English. Publication style guides, such as “The Economist Style Guide” for English, are useful resources.If your language has both upper and lowercase letters, only include the lowercase (and İ for Turkish and similar languages). |
| index | A B C D E F G H I J K L M N O P Q R S T U V W X Y Z | The “shortcut” letters for quickly jumping to sections of a sorted, indexed list (for an example, see mu.edu). The choice of letters should be appropriate for your language. Unlike the minimal or additional characters, it should have either uppercase or lowercase, depending on what is typical for your language (typically uppercase). Consider which characters from the auxiliary category need to be included in the index so that foreign words are properly indexed. For example, if the language doesn’t normally use “Q” it may still be wise to include “Q” in the index exemplar list so that “Qatar” doesn’t end up grouped under “P”. |
| <hr/> | <hr/> | <hr/> |
| numbers | - ‑ , . % ‰ + − 0 1 2 3 4 5 6 7 8 9 | The characters used in formatted numbers customarily used with your language. |
| numbers-auxiliary | The characters used in formatted numbers that are not commonly used used with your language, but may sometimes be used with foreign, old-fashioned, or technical text (like the difference between standard and auxiliary above). In some languages, these will be from traditional numbering systems. Add them here instead of in auxiliary. | |
| <hr/> | <hr/> | <hr/> |
| punctuation | - ‐ ‑ – — , ; : ! ? . … ‘ ‘ ’ “ “ ” ( ) [ ] § @ * / & # † ‡ ′ ″ | The punctuation characters customarily used with your language. For example, compared to the English list, Arabic might remove ; , ? /, and add ؟ \ ، ؛. Don’t include pure math symbols such as +, =, ±, and so on. |
| punctuation-person | - ‐ ‑ , . / | The punctuation symbols that are customarily used in people’s names in standard documents. This should normally be a small subset of the regular punctuation (see the English example). Do not include ‘fanciful’ characters such as emoji or kaomoji. |
| punctuation-auxiliary | The punctuation symbols that are not commonly used used with your language, but may sometimes be used with foreign, old-fashioned, or technical text (like the difference between standard and auxiliary above). Add them here instead of in auxiliary. |
Parse Characters
These are sets of characters that are treated as equivalent in parsing. In the Code column you’ll see a description of the characters with a sample in parentheses. For example, the following indicates that in date/time parsing, when someone types any of the characters in the Winning column, they should be treated as equivalent to “:”.
Note that if your language doesn’t use any of these characters in date and times, the value doesn’t really matter, and you can simply vote for the default value. For example, if a time is represented by “3.20” instead of “3:20”, then it doesn’t matter which characters are equivalent to “:”.


Handling Warnings in Exemplar characters
There are two kinds of warnings you can get with Exemplar Characters. While these are categorized as warnings, every effort should be made to fix them.
A. A particular translated item contains characters that aren’t in the exemplars.
For example:
- Suppose the currency code XAF is translated as “Φράγκο BEAC CFA” in Greek. That raises a warning because the “BEAC CFA” are not in the Greek exemplars.
- Suppose that a currency symbol contains ৲ (BENGALI RUPEE MARK). That also raises a warning, even though it is a symbol and not a letter, because it has a script (Bengali).
Three possible solutions:
- If the character really is used in the language, add it to the appropriate exemplar set (standard, auxiliary,…).
- For example, the Bengali Rupee mark should be added to the currency exemplar set.
- To add to the Exemplar Characters, go first to the main view for your locale, then select Other Items [Characters]. For example, see German characters.
- For currencies, if the character is part of a ‘gloss’, that is, it is parenthetically included for reference, and the gloss is all ASCII, then include it in brackets. You can use [square brackets] or (parentheses) in currencies. Everywhere else, please use only square brackets.
- So the XAF above can be fixed by changing it to “Φράγκο [BEAC CFA]” or “Φράγκο (BEAC CFA)”. For the timezone name “ACT (Ακρ)”, the fix is to change to “Ακρ [ACT]”.
- If neither of these approaches is appropriate, try rephrasing the translated item to avoid the character.
- If it really can’t be avoided, then please file a new ticket describing the problem.
B. The exemplar characters shouldn’t contain a particular character.
The standard characters shouldn’t contain punctuation. They also should not contain symbols, unless those symbols are only used with the language’s writing system (aka script). For example, the standard Bengali currency symbols should contain the Bengali Rupee mark (which is Bengali-only), but should not include the $ Dollar Sign (which is common across all scripts).