Language Support Levels
People often ask whether some device or application supports their language. This seems like a simple question: yes or no. But the reality is that there are different levels of support for a language, ranging from allowing the user to read their language on the platform all the way up to having a voice assistant in their language.
This page defines a common set of terminology for language support levels for platforms such as operating systems, browsers, etc. The goal is to have consistent terminology so that people can clearly indicate the level of support for a given language.
The focus here is on the incremental changes necessary to add a language to a platform that is already a Unicode-Enabled Platform. Note that the term ‘language’ is used for familiarity, but what needs to be supported are locales.
Support Levels
- Display - Text in the language can be read by users of the platform.
- Characters needed for the language are in Unicode.
- Fonts supporting those characters are installed (or installable) on the platform
- The rendering system supports the language’s script.
- line-break: Most languages are handled well by the default Unicode algorithms. Those not using spaces between words need extra support, eg in ICU.
- Bidirectional handling: those languages written right-left are handled (Hebrew, Arabic, …)
- Complex shaping is supported, eg, for scripts of South and Southeast Asia. The platform supports the Universal Shaping Engine (USE) and/or Harfbuzz, or equivalent.
- Input - Text in the language can be entered on the platform.
- Display Support Level, and
- A keyboard supporting the characters and customary layout for the language is installed (or installable) on the platform. This may also require an Input Method Engine for large scripts or complex scripts.
- Editing support: Cursor keys work, double-click for word selection, etc.
- Selection - The language (locale) can be selected as one of the user’s preferred languages for the platform, which is propagated to applications, fonts, etc.
- Input Support Level, and
- The language is supported by Unicode CLDR — reaching the CLDR Basic Level.
- The language is included in ICU or equivalent libraries.
- Language detection is available.
- Minimal i18n - The language has app-level internationalization services: sorting; basic dates & times (inc. intervals), basic numbers & currencies & units; names of major languages, countries, scripts, time zones, units
- Locale Support Level, and
- The language reaches the CLDR Moderate Level.
- Full i18n - The language has higher-level internationalization services: full formatting for dates & times (inc. relative), full numbers & currencies (inc compact) & units; names for all countries, time zones, languages, modern scripts, most locale options; names and search keywords for emoji and other symbols, font styles
- Minimal i18n Support Level, and
- The language reaches the CLDR Modern Level.
- UI - The platform and major apps on the platform have translated UI (menus, dialogs, etc.)
- Full i18n Support Level (in exceptional cases, Minimal i18n Support), and
- Business justification⭑
- The ongoing cost of translation is substantial, so the choice of languages at this level depends on a variety of factors. For example, a high potential number of new users (who couldn’t otherwise use the platform).
- Advanced (Natural language handling) - The platform offers advanced language services such as spelling correction, hyphenation, voice assistance, predictive keyboards, machine translation, transliteration, optical character recognition, speech to text (STT), text to speech (TTS), natural language processing (NLP), natural language understanding NLU, etc.
- Full i18n Support Level (in exceptional cases, down to Locale Support), and
- Business justification⭑
- These services typically require a substantial outlay of resources.
Notes:
- The term ‘language’ is used for familiarity, but what needs to be supported are locales.
- Some languages can be written with different scripts, such as Latin or Cyrillic. For the purpose of these levels, each <language, script> combination is treated as a separate language.
- Often languages have regional variants, where various features (like date formats or spelling) differ by the country or region. Typically they can inherit most of their support from a supported language, and only need small changes for support at most levels.
- The business justification is not listed for Levels 1-5, because the cost is far lower for those levels once a platform is Unicode Enabled. There is ongoing effort/cost to adding & maintaining higher levels of coverage of a language in CLDR, but many language communities successfully organize to manage that.
Applications
These levels also apply to individual applications, with some adjustments. For example, typically applications can only support languages that are Selectable on the platform. But once that level is reached, an application can often support a language at a higher level than the platform can.
Good applications and services will often allow choice of different languages. For example, a word processor can offer a menu for picking the language of selected text, so that that text can be handled in accordance with the selected language in operations like spell-checking. A spreadsheet can format dates in one column in French, and a second column in Russian. (This choice of language is independent of the language of the UI for the application or service.)
Language Characteristics
There are several general characteristics of languages, based on the kinds of technology that is needed to support them. These characteristics are all orthogonal (at least in principle) and all on a spectrum. This is just a summary; there are many other sources that go into more detail.
- Exemplar Set Size - The set of characters used by the language is large enough that it doesn’t fit on a keyboard.
- Examples of large exemplar set languages: Japanese, Chinese, Korean
- Display Complexity - The glyphs used to represent a string of characters in the language are context-dependent; sequence of glyphs is not simply a 1:1 match to the sequence of characters, and the glyph for a character may be very different depending on what characters are around it. A language written right to left (aka Bidi) also has a complex display.
- Examples of complex display languages: Hindi, Tamil; Arabic, Hebrew
- Degree of Inflection - very roughly, how much words in the language need to change form depending on context. Typically the most important feature for message support.
- Examples of highly inflected languages: Most Slavic languages (eg, Czech), some Indo-Aryan languages (eg, Marathi), Arabic, Finnish, Turkish
In general, the smaller the exemplar set, the simpler the display, and the fewer inflections, the easier it is to support a language on computers. However, when a platform or application is already able to handle a language with a certain set of characteristics, it is much easier to add other languages with those characteristics. So in general, if a platform handles a spread of languages like Japanese, Tamil, Arabic, Russian, and Turkish, it is easier to add support for other languages.
Other Resources
There are also good resources from a variety of sources, such as:
- https://www.w3.org/International/
- https://srl295.github.io/2017/06/06/full-stack-enablement/
- https://translationcommons.org/impact/language-digitization/resources/
- [TBD: ADD MORE]
CLDR Coverage Levels
CLDR provides different coverage levels, referenced by the above table.
Basic coverage - Selection
The most basic language support requires Unicode characters for writing that language, the Unicode properties and algorithms for those characters that let them work on computers and phones (such as line-wrapping), the fonts used to display those characters, and the keyboard layouts needed to enter those characters.
That is, the text is interchangeable across devices, it displays as expected on any device (given fonts), and users can enter and edit text in that language.
Moderate coverage - Minimal i18n support
For content language support, the user sees correct processing for that language, with sorting, matching, display and entry of dates, times, numbers, currencies, and so on. This requires data and algorithms that support these features, so that a phone or other device knows to display a date as “Freitag, 13. Januar 2012” or “Παρασκευή, 13 Ιανουαρίου 2012”.
Modern coverage - Full i18n support
For UI-language support, the language is also supported in the user interface of an application, web page, or OS: All of the menus, dialogs, help-text, and so on are in the user’s language. The user doesn’t need to know another language in order to use the application, web page, or OS.
Of course, more sophisticated programs will further layer on top of UI or content language support to offer capabilities that depend on language: complex searching algorithms will identify entities in the text, and allow for matching that takes into account linguistic synonyms and inflections; text-to-speech and speech-to-text capabilities allow the user to easily interact with a device, and so on. These tend to require very sophisticated machine-learning models, typically based on massive amounts of data.
In practice
Much of the world is multilingual, and people are often fluent enough in a second language to be able to use that as their UI language. But they still want and need to be able to use their language as a content language. Take Yoruba, for example, with ca. 30 million speakers. A Yoruba speaker may be able to use English as their UI language, but still needs to be able to write emails in Yoruba, compose documents in Yoruba, and create a spreadsheet in Yoruba. To help with language preservation, content language support on digital devices is an important step above basic language support.
The Unicode Consortium enables vendors to support additional content languages by providing the characters those languages need, the properties and algorithms for those characters that let them work on computers and phones (line break, …), and core linguistic support (sorting, matching; keyboard layouts; entering/displaying dates, times, numbers, currencies, measurements, country names,…). The consortium doesn’t supply fonts, but those are available from other sources, such as Google’s Noto fonts project (free, under the open font license).
The consortium also offers some support for UI language support in CLDR and ICU, but most of the work necessary to support a given language as a UI language depends on the app or OS provider doing the necessary translations.
Example: Cherokee
For basic language support, characters for Cherokee had to be added to Unicode, since it doesn’t use the Latin characters (A, B, C, … ). The Unicode properties had to be supplied, so that the standard Unicode algorithms would work for for text comparison, line-wrap, word selection, and so on. Fonts and keyboard layouts for Cherokee are available, but might require an additional step for installation if not already on the OS. The content language support for dates, times, and other features are provided for in CLDR.
Developers can produce apps that support Cherokee as a content language using the Unicode ICU libraries. It supplies them with the code to handle the necessary Unicode characters, properties and algorithms, and the CLDR content-language data.
Systems that support the most up-to-date Unicode ICU libraries (like Android or the Mac) should see Cherokee as a choice among languages. For example, on a Mac someone can pick a Cherokee keyboard, and type in GMail the Cherokee characters:
Language selection UI
Below are examples of selecting Cherokee on different systems. (Cherokee in Cherokee looks like “CWY”, and is midway down on each.)
| Android | Macintosh | Windows |
|---|---|---|
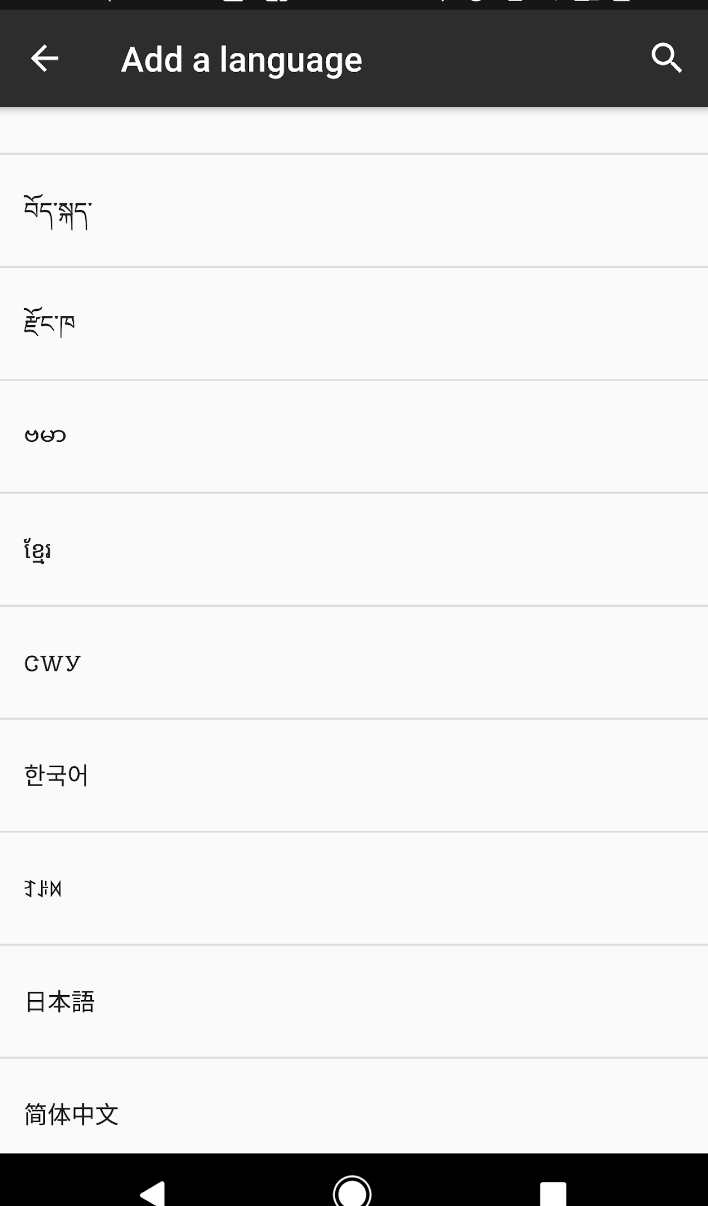 |
 |
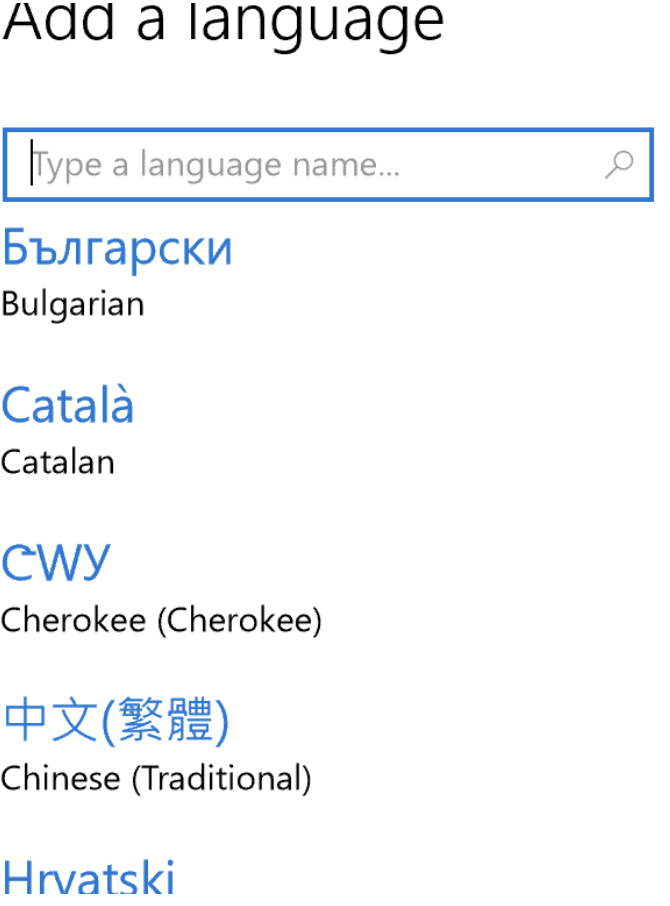 |
Cherokee is not typically a UI language for the OS, meaning the system isn’t translated into it. So in practice a user must also select an alternative language such as English that will appear in the UI for any applications that don’t support Cherokee.